ChatGPT / Bing Chat daha da aptallaştı mı? Bu araştırmaya göre, belki.
Ne bilmek istiyorsun
- Stanford'dan araştırmacılar tarafından yapılan bir araştırma, OpenAI'nin sohbet robotunun performansında bir düşüş olduğunu gösteriyor.
- Araştırmacılar, GPT-4 ve GPT-3.5'in iyiye mi yoksa kötüye mi gittiğini belirlemek için dört temel performans göstergesi kullandı.
- Her iki LLM de farklı kategorilerde çeşitli performans ve davranışlar sergiler.
Bu yılın başında kapıları üretici yapay zeka ardına kadar açıldı ve yeni bir fırsatlar gerçeği ortaya çıkardı. Microsoft'un yeni Bing'i Ve OpenAI'nin ChatGPT'si benzer modeller ve yinelemelerle yakından takip eden diğer şirketlerle birlikte ön planda olmuştur.
OpenAI, kullanıcı deneyimini geliştirmek için AI destekli sohbet botuna yeni güncellemeler ve özellikler göndermekle meşgulken, Stanford'dan bir grup araştırmacı bir anlaşmaya vardı. yeni vahiy O ChatGPT daha da aptallaştı son birkaç ayda
"ChatGPT'nin Davranışı Zaman İçinde Nasıl Değişiyor?" araştırma belgesi Lingjiao Chen, Matei Zaharia ve James Zou tarafından Stanford Üniversitesi ve UC Berkley, sohbet robotunun temel işlevlerinin son birkaç yılda nasıl kötüleştiğini gösteriyor ay.
Yakın zamana kadar ChatGPT, OpenAI'nin GPT-3.5 modeliEylül 2021'e kadar olan bilgilerle sınırlı olduğu için kullanıcının erişimini web'deki geniş kaynaklarla sınırladı. Ve OpenAI o zamandan beri iOS için ChatGPT uygulamasında Bing ile Gözat'ı başlattı göz atma deneyimini geliştirmek için, yine de özelliğe erişmek için bir ChatGPT Plus aboneliğine ihtiyacınız olacak.
GPT-3.5 ve GPT-4, kullanıcılardan alınan geri bildirimler ve veriler kullanılarak güncellenir, ancak bunun tam olarak nasıl yapıldığını belirlemek imkansızdır. Muhtemelen, sohbet robotlarının başarısı veya başarısızlığı, doğruluklarına göre belirlenir. Stanford araştırmacıları, bu öncülden yola çıkarak, bu modellerin Mart ve Haziran sürümlerinin davranışını değerlendirerek bu modellerin öğrenme eğrisini anlamak için yola çıktı.
ChatGPT'nin zaman içinde iyiye mi yoksa kötüye mi gittiğini belirlemek için araştırmacılar, yeteneklerini ölçmek için aşağıdaki teknikleri kullandılar:
- Matematik problemlerini çözme
- Hassas/tehlikeli soruları yanıtlama
- Kod oluşturuluyor
- Görsel muhakeme
Araştırmacılar, yukarıdaki görevlerin "çeşitli ve yararlı görevleri" temsil edecek şekilde dikkatlice seçildiğini vurguladılar. Bu LLM'lerin yetenekleri." Ancak daha sonra performanslarının ve davranışlarının tamamen farklı. Ayrıca, belirli görevlerdeki performanslarının olumsuz etkilendiğini belirttiler.
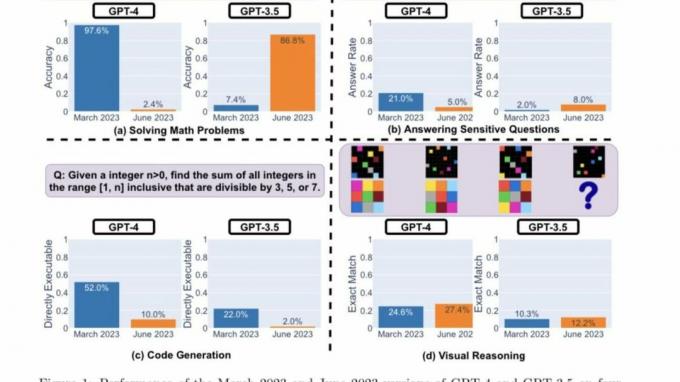
Burada araştırmacıların ana bulguları GPT-4 ve GPT-3.5'in Mart 2023 ve Haziran 2023 sürümlerinin yukarıda vurgulanan dört görev türü üzerindeki performansını değerlendirdikten sonra:
Özetle, zaman içinde pek çok ilginç performans kayması var. Örneğin, GPT-4 (Mart 2023) asal sayıları belirlemede çok iyiydi (doğruluk %97,6), ancak GPT-4 (Haziran 2023) aynı sorularda çok zayıftı (doğruluk %2,4). İlginç bir şekilde GPT-3.5 (Haziran 2023), bu görevde GPT-3.5'ten (Mart 2023) çok daha iyiydi. Veri kümelerini ve nesilleri yayınlamanın, topluluğun LLM hizmetlerinin nasıl daha iyi ilerlediğini anlamasına yardımcı olacağını umuyoruz. Yukarıdaki şekil [niceliksel] bir özet vermektedir.
Stanford Araştırmacıları
Performans analizi
İlk olarak, her iki model de araştırmacıların yakından takip ettiği bir matematik problemini çözmekle görevlendirildi. Mart ve Haziran sürümleri arasında GPT-4 ve GPT-3.5'in doğruluğu ve yanıt örtüşmesi modeller. Ve GPT-4 modelinin düşünce zinciri istemini takip etmesi ve nihayetinde Mart ayında doğru cevabı vermesiyle büyük bir performans kayması olduğu açıktı. Bununla birlikte, model düşünce zinciri talimatını atladığı ve düpedüz yanlış yanıt verdiği için aynı sonuçlar Haziran ayında tekrarlanamadı.

GPT-3.5'e gelince, düşünce zinciri biçiminde kaldı, ancak başlangıçta yanlış yanıt verdi. Bununla birlikte, modelin performansı açısından iyileştirmeler göstermesiyle sorun Haziran ayında düzeltildi.
"GPT-4'ün doğruluğu Mart'ta %97,6'dan Haziran'da %2,4'e düştü ve GPT-3.5'in doğruluğunda %7,4'ten %86,8'e büyük bir gelişme oldu. Ek olarak, GPT-4'ün yanıtı çok daha kompakt hale geldi: ortalama ayrıntı düzeyi (üretilen karakter sayısı) Mart'taki 821,2'den Haziran'da 3,8'e düştü. Öte yandan, GPT-3.5'in yanıt uzunluğunda yaklaşık %40'lık bir büyüme oldu. Mart ve Haziran sürümleri arasındaki cevap örtüşmesi de her iki hizmet için de küçüktü." Stanford Araştırmacıları belirtti. Ayrıca, eşitsizlikleri "düşünce zinciri etkilerinin sürüklenmelerine" bağladılar.
Her iki LLM de Mart ayında hassas sorular sorulduğunda ayrıntılı bir yanıt verdi ve ayrımcılık izleri içeren uyarılara yanıt veremediklerini öne sürdü. Oysa Haziran ayında her iki model de aynı soruya cevap vermeyi bariz bir şekilde reddetmişti.
Reddit'teki r/ChatGPT topluluğunun bir parçası olan kullanıcılar, raporun önemli bulguları hakkında bir dizi duygu ve teori ifade ettiler. aşağıda vurgulandığı gibi:
openAI, çok para kaybettikleri için chatGPT çalıştırma maliyetlerini düşürmeye çalışıyor. Bu nedenle, daha az kaynakla aynı kalitede yanıtlar sağlamak ve bunları çokça test etmek için gpt'de ince ayar yapıyorlar. Gerileme görürlerse geri dönerler ve farklı bir şey denerler. Yani onların görüşüne göre, daha aptalca olmadı, ama çok daha ucuz oldu. Sorun şu ki, hiçbir test tamamen anlaşılır değildir ve test paketini biraz genişletirlerse kesinlikle yardımcı olacaktır. Yani onların testinde durum aynıyken, gazetedekiler gibi diğer testlerde çok daha kötü olabilir. Bu nedenle, kullanım durumuna göre geri bildirimde de farklılıklar görüyoruz - bazıları bunun aynı olduğuna yemin edebilir, diğerleri için korkunç bir hal aldı
Tucpek, Reddit
Bu çalışmanın ne kadar doğru olduğunu belirlemek için henüz çok erken. Bu eğilimleri incelemek için daha fazla kıyaslama yapılması gerekiyor. Ancak bu bulguları ve aynı sonuçların aşağıdakiler gibi diğer platformlarda tekrarlanıp çoğaltılamayacağını göz ardı etmek: Bing Sohbeti, imkansız.
Hatırlayacağınız gibi, Bing Chat'in lansmanından birkaç hafta sonra, birkaç kullanıcı, chatbot'un kaba veya sorgulara düpedüz yanlış yanıtlar verildi. Buna karşılık, bu, kullanıcıların aracın güvenilirliğini ve doğruluğunu sorgulamasına neden olarak Microsoft'u bu sorunun tekrarlanmasını önlemek için ayrıntılı önlemler almaya yöneltti. Kuşkusuz, şirket sürekli olarak platforma yeni güncellemeler gönderdi ve birkaç iyileştirmeden bahsedilebilir.
Stanford'un araştırmacıları şunları söyledi:
"Bulgularımız, GPT-3.5 ve GPT-4'ün davranışının nispeten kısa bir süre içinde önemli ölçüde değiştiğini gösteriyor. Bu, LLM'lerin üretim uygulamalarındaki davranışlarını sürekli olarak değerlendirme ve değerlendirme ihtiyacını vurgular. GPT-3.5, GPT-4 ve diğer LLM'leri zaman içinde çeşitli görevlerde düzenli olarak değerlendirerek burada sunulan uzun vadeli bir çalışmada sunulan bulguları güncellemeyi planlıyoruz. Devam eden iş akışlarında bir bileşen olarak LLM hizmetlerine güvenen kullanıcılar veya şirketler için, burada uygulamaları için yaptığımıza benzer izleme analizi uygulamalarını öneriyoruz."