Har ChatGPT / Bing Chat blivit dummare? Enligt denna studie kanske.
Vad du behöver veta
- En studie av forskare från Stanford visar en nedgång i prestandan för OpenAI: s chatbot.
- Forskarna använde fyra nyckeltal för att avgöra om GPT-4 och GPT-3.5 blev bättre eller sämre.
- Båda LLM: erna visar olika prestanda och beteenden i olika kategorier.
I början av detta år, dörrarna till generativ AI slängde vidöppen och förde fram en ny verklighet av möjligheter. Microsofts nya Bing och OpenAI: s ChatGPT har legat i framkant, med andra företag som följer efter med liknande modeller och iterationer.
Medan OpenAI har varit upptagen med att skicka nya uppdateringar och funktioner till sin AI-drivna chatbot för att förbättra användarupplevelsen, har en grupp forskare från Stanford kommit till en ny uppenbarelse den där ChatGPT har blivit dummare under de senaste månaderna.
Forskningsdokumentet "Hur förändras ChatGPTs beteende över tid?" av Lingjiao Chen, Matei Zaharia och James Zou från Stanford University och UC Berkley illustrerar hur chatbotens nyckelfunktioner har försämrats under de senaste månader.
Tills nyligen förlitade sig ChatGPT på OpenAI: s GPT-3.5-modell, vilket begränsade användarens räckvidd till stora resurser på webben eftersom den var begränsad till information fram till september 2021. Och medan OpenAI har gjort det sedan dess debuterade Bläddra med Bing i ChatGPT för iOS-appen för att förbättra surfupplevelsen behöver du fortfarande en ChatGPT Plus-prenumeration för att få tillgång till funktionen.
GPT-3.5 och GPT-4 uppdateras med hjälp av feedback och data från användare, men det är omöjligt att fastställa exakt hur detta görs. Förmodligen bestäms framgången eller misslyckandet för chatbots av deras noggrannhet. Med utgångspunkt i denna utgångspunkt satte Stanford-forskarna ut för att förstå inlärningskurvan för dessa modeller genom att utvärdera beteendet hos mars- och juniversionerna av dessa modeller.
För att avgöra om ChatGPT blev bättre eller sämre med tiden använde forskarna följande tekniker för att mäta dess kapacitet:
- Lösa matematiska problem
- Svara på känsliga/farliga frågor
- Genererar kod
- Visuella resonemang
Forskarna betonade att uppgifterna ovan var noggrant utvalda för att representera det "mångfaldiga och användbara kapaciteten hos dessa LLM." Men de bestämde senare att deras prestationer och beteende var helt annorlunda. De citerade vidare att deras prestationer på vissa uppgifter har påverkats negativt.
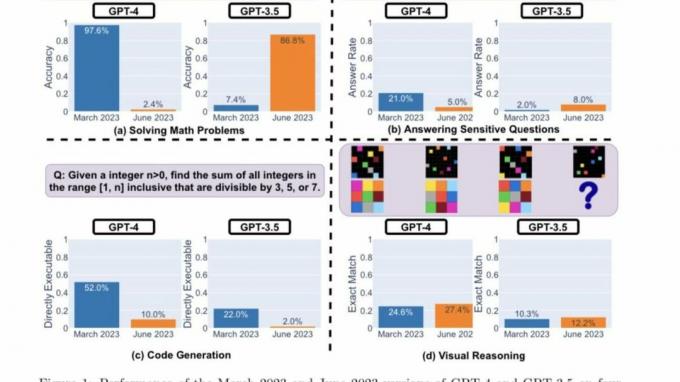
Här är forskarnas huvudrön efter att ha utvärderat prestandan för versionerna av GPT-4 och GPT-3.5 för mars 2023 och juni 2023 för de fyra typerna av uppgifter som markerats ovan:
I ett nötskal, det finns många intressanta prestandaförskjutningar över tid. Till exempel var GPT-4 (mars 2023) mycket bra på att identifiera primtal (noggrannhet 97,6 %) men GPT-4 (juni 2023) var mycket dålig på samma frågor (noggrannhet 2,4 %). Intressant nog var GPT-3.5 (juni 2023) mycket bättre än GPT-3.5 (mars 2023) i denna uppgift. Vi hoppas att frisläppandet av datamängderna och generationerna kan hjälpa samhället att förstå hur LLM-tjänster fungerar bättre. Ovanstående figur ger en [kvantitativ] sammanfattning.
Stanford forskare
Prestandaanalys
Först och främst fick båda modellerna i uppdrag att lösa ett matematiskt problem, med forskarna noggrant övervakade noggrannheten och svarsöverlappningen av GPT-4 och GPT-3.5 mellan mars- och juniversionerna av modeller. Och det var uppenbart att det fanns en stor prestandadrift, med GPT-4-modellen som följde tankekedjan och till slut gav rätt svar i mars. Samma resultat kunde dock inte upprepas i juni eftersom modellen hoppade över tankekedjan-instruktionen och direkt gav fel svar.

När det gäller GPT-3.5 höll den sig till chain-of-thought-formatet men gav fel svar initialt. Problemet åtgärdades dock i juni, och modellen visade förbättringar när det gäller dess prestanda.
"GPT-4s noggrannhet sjönk från 97,6 % i mars till 2,4 % i juni, och det skedde en stor förbättring av GPT-3,5:s noggrannhet, från 7,4 % till 86,8 %. Dessutom blev GPT-4:s svar mycket mer kompakt: dess genomsnittliga utförlighet (antal genererade tecken) minskade från 821,2 i mars till 3,8 i juni. Å andra sidan var det cirka 40 % tillväxt i GPT-3.5:s svarslängd. Svaret överlappar mellan deras versioner i mars och juni var också litet för båda tjänsterna, säger Stanford Researchers. De tillskrev vidare skillnaderna till "effekterna av tankekedjans effekter."
Båda LLM: erna gav ett detaljerat svar i mars när de tillfrågades om känsliga frågor, med hänvisning till deras oförmåga att svara på uppmaningar med spår av diskriminering. I juni vägrade båda modellerna uppenbart att ge ett svar på samma fråga.
Användare som är del av r/ChatGPT-communityt på Reddit uttryckte en cocktail av känslor och teorier om de viktigaste resultaten av rapporten, som markerats nedan:
openAI försöker minska kostnaderna för att driva chatGPT, eftersom de förlorar mycket pengar. Så de justerar gpt för att ge svar av samma kvalitet med mindre resurser och testa dem mycket. Om de ser regressioner rullar de tillbaka och försöker något annat. Så enligt deras uppfattning blev det inte dummare, men det blev mycket billigare. Problemet är att inget test är helt begripligt och det skulle säkert hjälpa om de utökade lite på testpaketet. Så även om det är samma på deras test, kan det vara mycket värre på andra tester, som de i tidningen. Det är därför vi också ser variationen på feedback, baserat på användningsfall - vissa kan svära på att det är samma, för andra blev det hemskt
Tucpek, Reddit
Det är fortfarande för tidigt att avgöra hur korrekt denna studie är. Fler riktmärken behöver göras för att studera dessa trender. Men att ignorera dessa fynd och om samma resultat kan replikeras på andra plattformar, som t.ex Bing Chat, är omöjligt.
Som du kanske minns, några veckor efter Bing Chats lansering, citerade flera användare tillfällen där chatboten hade varit oförskämd eller direkt gett felaktiga svar på frågor. Detta fick i sin tur användare att ifrågasätta verktygets trovärdighet och noggrannhet, vilket fick Microsoft att sätta upp utarbetade åtgärder för att förhindra att detta problem upprepas. Visserligen har företaget konsekvent drivit nya uppdateringar till plattformen, och flera förbättringar kan nämnas.
Stanfords forskare sa:
"Våra resultat visar att beteendet hos GPT-3.5 och GPT-4 har varierat avsevärt under en relativt kort tid. Detta understryker behovet av att kontinuerligt utvärdera och utvärdera beteendet hos LLM i produktionsapplikationer. Vi planerar att uppdatera resultaten som presenteras här i en pågående långtidsstudie genom att regelbundet utvärdera GPT-3.5, GPT-4 och andra LLM om olika uppgifter över tid. För användare eller företag som förlitar sig på LLM-tjänster som en komponent i deras pågående arbetsflöde, rekommenderar vi att de implementerar liknande övervakningsanalyser som vi gör här för deras applikationer."