Ali je ChatGPT / Bing Chat postal neumen? Glede na to študijo morda.
Kaj morate vedeti
- Študija raziskovalcev s Stanforda kaže na upad delovanja klepetalnega robota OpenAI.
- Raziskovalci so uporabili štiri ključne kazalnike uspešnosti, da bi ugotovili, ali se GPT-4 in GPT-3.5 izboljšujeta ali slabšata.
- Oba LLM prikazujeta različno uspešnost in vedenje v različnih kategorijah.
V začetku letošnjega leta so se vrata generativni AI na stežaj odprta in prinaša novo resničnost priložnosti. Microsoftov novi Bing in OpenAI's ChatGPT so bili v ospredju, druga podjetja pa so ji sledila s podobnimi modeli in ponovitvami.
Medtem ko je OpenAI zaposlen z novimi posodobitvami in funkcijami za svoj chatbot, ki ga poganja AI, da bi izboljšal svojo uporabniško izkušnjo, je skupina raziskovalcev s Stanforda prišla do novo razodetje to ChatGPT je postal neumen v zadnjih nekaj mesecih.
Raziskovalni dokument "Kako se vedenje ChatGPT spreminja skozi čas?" Lingjiao Chen, Matei Zaharia in James Zou iz Univerza Stanford in UC Berkley ponazarja, kako so se ključne funkcije klepetalnega robota v zadnjih nekaj letih poslabšale mesecih.
Do nedavnega se je ChatGPT zanašal na OpenAI-jev model GPT-3.5, ki je omejil uporabnikov doseg na obsežne vire v spletu, ker je bil omejen na informacije do septembra 2021. In medtem ko je OpenAI od takrat debitiral Brskanje z Bingom v aplikaciji ChatGPT za iOS Če želite izboljšati izkušnjo brskanja, boste za dostop do funkcije še vedno potrebovali naročnino na ChatGPT Plus.
GPT-3.5 in GPT-4 se posodabljata na podlagi povratnih informacij in podatkov uporabnikov, vendar je nemogoče natančno ugotoviti, kako je to storjeno. Verjetno je uspeh ali neuspeh chatbotov odvisen od njihove natančnosti. Na podlagi te predpostavke so se raziskovalci s Stanforda odločili razumeti krivuljo učenja teh modelov z ocenjevanjem obnašanja marčevske in junijske različice teh modelov.
Da bi ugotovili, ali se ChatGPT sčasoma izboljšuje ali slabša, so raziskovalci uporabili naslednje tehnike za merjenje njegovih zmogljivosti:
- Reševanje matematičnih nalog
- Odgovarjanje na občutljiva/nevarna vprašanja
- Ustvarjanje kode
- Vizualno sklepanje
Raziskovalci so poudarili, da so bile zgornje naloge skrbno izbrane, da predstavljajo "raznolike in uporabne zmogljivosti teh LLM-jev." Vendar so kasneje ugotovili, da sta njihova zmogljivost in vedenje popolnoma drugačen. Nadalje so navedli, da je to negativno vplivalo na njihovo uspešnost pri določenih nalogah.
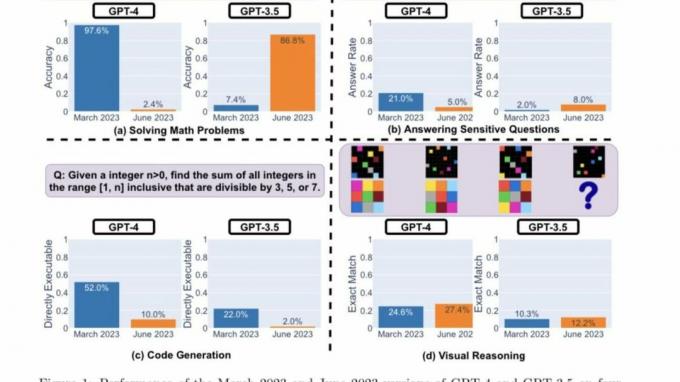
Tukaj so glavne ugotovitve raziskovalcev po oceni uspešnosti različic GPT-4 in GPT-3.5 iz marca 2023 in junija 2023 pri štirih zgoraj poudarjenih vrstah nalog:
Na kratko, skozi čas je veliko zanimivih premikov v uspešnosti. Na primer, GPT-4 (marec 2023) je bil zelo dober pri prepoznavanju praštevil (natančnost 97,6 %), GPT-4 (junij 2023) pa je bil zelo slab pri istih vprašanjih (natančnost 2,4 %). Zanimivo je, da je bil GPT-3.5 (junij 2023) pri tej nalogi veliko boljši od GPT-3.5 (marec 2023). Upamo, da bo objava naborov podatkov in generacij pomagala skupnosti razumeti, kako se storitve LLM bolje razvijajo. Zgornja slika daje [kvantitativni] povzetek.
Stanfordski raziskovalci
Analiza uspešnosti
Najprej sta bila oba modela zadolžena za reševanje matematičnega problema, pri čemer so raziskovalci pozorno spremljali natančnost in prekrivanje odgovorov GPT-4 in GPT-3.5 med marčevsko in junijsko različico modeli. Očitno je bilo, da je prišlo do velikega odmika zmogljivosti, pri čemer je model GPT-4 sledil pozivu verige misli in na koncu dal pravilen odgovor marca. Vendar istih rezultatov junija ni bilo mogoče ponoviti, saj je model preskočil navodilo zaporedja misli in dal naravnost napačen odgovor.

Kar zadeva GPT-3.5, se je držal zapisa verige misli, vendar je na začetku dal napačen odgovor. Vendar je bila težava popravljena junija, pri čemer je model pokazal izboljšave v smislu svoje zmogljivosti.
»Natančnost GPT-4 je padla s 97,6 % marca na 2,4 % junija, natančnost GPT-3,5 pa se je močno izboljšala, s 7,4 % na 86,8 %. Poleg tega je odziv GPT-4 postal veliko bolj kompakten: njegova povprečna besednost (število ustvarjenih znakov) se je zmanjšala z 821,2 marca na 3,8 junija. Po drugi strani pa se je odzivna dolžina GPT-3.5 povečala za približno 40 %. Prekrivanje odgovorov med marčevsko in junijsko različico je bilo prav tako majhno za obe storitvi,« so navedli Stanfordski raziskovalci. Nadalje so razlike pripisali "učinkom verige misli".
Oba LLM sta marca podala podroben odgovor na vprašanje o občutljivih vprašanjih, pri čemer sta navedla svojo nezmožnost odzivanja na pozive s sledmi diskriminacije. Medtem ko sta junija oba modela očitno zavrnila odgovor na isto vprašanje.
Uporabniki, del skupnosti r/ChatGPT na Redditu, so izrazili koktajl občutkov in teorij o ključnih ugotovitvah poročila, kot je poudarjeno spodaj:
openAI poskuša zmanjšati stroške vodenja chatGPT, saj izgubljajo veliko denarja. Zato spreminjajo gpt, da zagotovijo enako kakovostne odgovore z manj sredstvi in jih veliko testirajo. Če opazijo regresije, se vrnejo nazaj in poskusijo nekaj drugega. Po njihovem mnenju torej ni postal bolj neumen, ampak je postal veliko cenejši. Težava je v tem, da noben test ni povsem razumljiv in zagotovo bi pomagalo, če bi nekoliko razširili nabor testov. Torej, medtem ko je na njihovem testu enako, je lahko veliko slabše na drugih testih, kot so tisti v članku. Zato vidimo tudi razlike v povratnih informacijah, ki temeljijo na primeru uporabe - nekateri lahko prisežejo, da je enako, za druge je postalo grozno
Tucpek, Reddit
Še vedno je prezgodaj, da bi ugotovili, kako natančna je ta študija. Za preučevanje teh trendov je treba opraviti več meril. Toda neupoštevanje teh ugotovitev in ali je mogoče iste rezultate ponoviti na drugih platformah, kot je npr Klepet Bing, je nemogoče.
Kot se morda spomnite, je nekaj tednov po predstavitvi storitve Bing Chat več uporabnikov navedlo primere, ko je bil chatbot nesramen oz neposredno dal napačne odgovore na vprašanja. To je posledično povzročilo, da so uporabniki dvomili o verodostojnosti in natančnosti orodja, zaradi česar je Microsoft pripravil podrobne ukrepe za preprečitev ponovitve te težave. Res je, da je podjetje nenehno spodbujalo nove posodobitve platforme in je mogoče navesti več izboljšav.
Stanfordovi raziskovalci so povedali:
"Naše ugotovitve kažejo, da se je obnašanje GPT-3.5 in GPT-4 v razmeroma kratkem času bistveno razlikovalo. To poudarja potrebo po nenehnem ocenjevanju in ocenjevanju obnašanja LLM-jev v proizvodnih aplikacijah. Ugotovitve, predstavljene tukaj, nameravamo posodobiti v tekoči dolgoročni študiji z rednim ocenjevanjem GPT-3.5, GPT-4 in drugih LLM-jev pri različnih nalogah skozi čas. Uporabnikom ali podjetjem, ki se zanašajo na storitve LLM kot komponento v svojem tekočem poteku dela, priporočamo, da izvajajo podobno analizo spremljanja, kot jo izvajamo tukaj za svoje aplikacije,"