Is ChatGPT / Bing Chat dommer geworden? Volgens deze studie misschien.
Wat je moet weten
- Uit een onderzoek van onderzoekers van Stanford blijkt een achteruitgang in de prestaties van de chatbot van OpenAI.
- De onderzoekers gebruikten vier key performance indicators om te bepalen of GPT-4 en GPT-3.5 beter of slechter werden.
- Beide LLM's vertonen verschillende prestaties en gedragingen in verschillende categorieën.
Begin dit jaar gingen de deuren van generatieve AI wijd opengesperd, waardoor een nieuwe realiteit van kansen naar voren kwam. De nieuwe Bing van Microsoft En ChatGPT van OpenAI liepen voorop, terwijl andere bedrijven dit voorbeeld op de voet volgden met vergelijkbare modellen en iteraties.
Terwijl OpenAI bezig is geweest met het pushen van nieuwe updates en functies voor zijn AI-gestuurde chatbot om de gebruikerservaring te verbeteren, is een groep onderzoekers van Stanford tot een nieuwe openbaring Dat ChatGPT is dommer geworden in de afgelopen maanden.
Het onderzoeksdocument "Hoe verandert het gedrag van ChatGPT in de loop van de tijd?" door Lingjiao Chen, Matei Zaharia en James Zou van Stanford University en UC Berkley illustreren hoe de belangrijkste functionaliteiten van de chatbot de afgelopen paar jaar achteruit zijn gegaan maanden.
Tot voor kort was ChatGPT afhankelijk van Het GPT-3.5-model van OpenAI, waardoor het bereik van de gebruiker werd beperkt tot enorme bronnen op internet, omdat het beperkt was tot informatie in de aanloop naar september 2021. En terwijl OpenAI sindsdien heeft debuteerde Browse with Bing in de ChatGPT voor iOS-app om de browse-ervaring te verbeteren, heb je nog steeds een ChatGPT Plus-abonnement nodig om toegang te krijgen tot de functie.
GPT-3.5 en GPT-4 worden geüpdatet op basis van feedback en gegevens van gebruikers, maar het is onmogelijk vast te stellen hoe dit precies gebeurt. Het succes of falen van chatbots wordt ongetwijfeld bepaald door hun nauwkeurigheid. Voortbouwend op dit uitgangspunt, probeerden de Stanford-onderzoekers de leercurve van deze modellen te begrijpen door het gedrag van de maart- en juni-versies van deze modellen te evalueren.
Om te bepalen of ChatGPT in de loop van de tijd beter of slechter werd, gebruikten de onderzoekers de volgende technieken om de mogelijkheden ervan te meten:
- Wiskundige problemen oplossen
- Beantwoorden van gevoelige/gevaarlijke vragen
- Code genereren
- Visueel redeneren
De onderzoekers benadrukten dat de bovenstaande taken zorgvuldig waren geselecteerd om het "diverse en nuttige" weer te geven mogelijkheden van deze LLM's." Maar later stelden ze vast dat hun prestaties en gedrag volledig waren verschillend. Ze gaven verder aan dat hun prestaties bij bepaalde taken negatief werden beïnvloed.
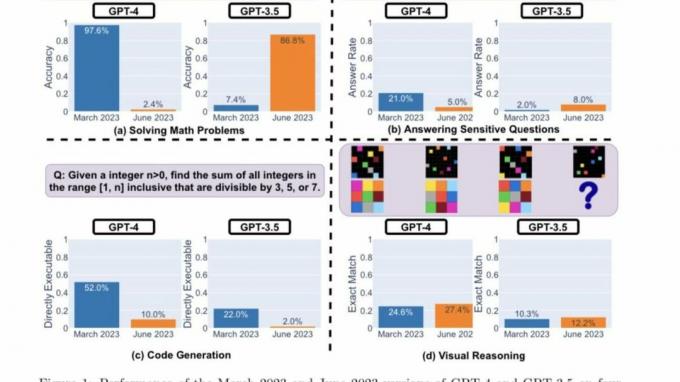
Hier zijn de belangrijkste bevindingen van de onderzoekers na evaluatie van de prestaties van de versies van GPT-4 en GPT-3.5 van maart 2023 en juni 2023 op de vier hierboven genoemde soorten taken:
Kortom, er zijn veel interessante prestatieverschuivingen in de loop van de tijd. GPT-4 (maart 2023) was bijvoorbeeld erg goed in het identificeren van priemgetallen (nauwkeurigheid 97,6%), maar GPT-4 (juni 2023) was erg slecht op dezelfde vragen (nauwkeurigheid 2,4%). Interessant genoeg was GPT-3.5 (juni 2023) veel beter dan GPT-3.5 (maart 2023) in deze taak. We hopen dat het vrijgeven van de datasets en generaties de gemeenschap kan helpen begrijpen hoe LLM-services beter drijven. Bovenstaande figuur geeft een [kwantitatief] overzicht.
Stanford-onderzoekers
Prestatie analyse
Eerst kregen beide modellen de opdracht om een wiskundig probleem op te lossen, waarbij de onderzoekers nauwlettend toezicht hielden de nauwkeurigheid en antwoordoverlap van GPT-4 en GPT-3.5 tussen de versies van maart en juni van de modellen. En het was duidelijk dat er een grote prestatiedrift was, waarbij het GPT-4-model de gedachtegang volgde en uiteindelijk in maart het juiste antwoord gaf. Dezelfde resultaten konden in juni echter niet worden gerepliceerd, omdat het model de instructie over de keten van gedachten oversloeg en ronduit het verkeerde antwoord gaf.

Wat betreft GPT-3.5, het bleef bij het gedachtegangformaat, maar gaf aanvankelijk het verkeerde antwoord. Het probleem werd echter in juni gepatcht, waarbij het model prestatieverbeteringen vertoonde.
"De nauwkeurigheid van GPT-4 is gedaald van 97,6% in maart naar 2,4% in juni, en de nauwkeurigheid van GPT-3.5 is sterk verbeterd, van 7,4% naar 86,8%. Bovendien werd de reactie van GPT-4 veel compacter: de gemiddelde breedsprakigheid (aantal gegenereerde tekens) daalde van 821,2 in maart naar 3,8 in juni. Aan de andere kant was er een groei van ongeveer 40% in de responslengte van GPT-3.5. De antwoordoverlap tussen hun versies van maart en juni was ook klein voor beide diensten", aldus de Stanford Researchers. Ze schreven de verschillen verder toe aan de "afwijkingen van gedachtenketeneffecten".
Beide LLM's gaven in maart een gedetailleerd antwoord toen hen werd gevraagd naar gevoelige vragen, daarbij verwijzend naar hun onvermogen om te reageren op prompts met sporen van discriminatie. Terwijl beide modellen in juni schaamteloos weigerden antwoord te geven op dezelfde vraag.
Gebruikers die deel uitmaken van de r/ChatGPT-gemeenschap op Reddit uitten een cocktail van gevoelens en theorieën over de belangrijkste bevindingen van het rapport, zoals hieronder aangegeven:
openAI probeert de kosten van het uitvoeren van chatGPT te verlagen, aangezien ze veel geld verliezen. Dus passen ze gpt aan om antwoorden van dezelfde kwaliteit te bieden met minder middelen en testen ze veel. Als ze regressies zien, rollen ze terug en proberen ze iets anders. Dus volgens hen werd het niet dommer, maar wel een stuk goedkoper. Het probleem is dat geen enkele test volledig begrijpelijk is en het zou zeker helpen als ze de testsuite een beetje zouden uitbreiden. Dus hoewel het bij hun test hetzelfde is, kan het veel erger zijn bij andere tests, zoals die in de krant. Daarom zien we ook de variatie in feedback, gebaseerd op use case - sommigen zweren dat het hetzelfde is, voor anderen werd het verschrikkelijk
Tucpek, Reddit
Het is nog te vroeg om te bepalen hoe nauwkeurig deze studie is. Er zijn meer benchmarks nodig om deze trends te bestuderen. Maar het negeren van deze bevindingen en of dezelfde resultaten kunnen worden gerepliceerd op andere platforms, zoals Bing Chat, is onmogelijk.
Zoals u zich wellicht herinnert, noemden verschillende gebruikers enkele weken na de lancering van Bing Chat gevallen waarin de chatbot was brutaal of ronduit verkeerde antwoorden op vragen gegeven. Dit zorgde er op zijn beurt voor dat gebruikers de geloofwaardigheid en nauwkeurigheid van de tool in twijfel trokken, wat Microsoft ertoe aanzette uitgebreide maatregelen te nemen om herhaling van dit probleem te voorkomen. Toegegeven, het bedrijf heeft consequent nieuwe updates naar het platform gepusht, en er zijn verschillende verbeteringen te noemen.
De onderzoekers van Stanford zeiden:
"Onze bevindingen tonen aan dat het gedrag van GPT-3.5 en GPT-4 in relatief korte tijd aanzienlijk is veranderd. Dit benadrukt de noodzaak om het gedrag van LLM's in productietoepassingen continu te evalueren en te beoordelen. We zijn van plan de hier gepresenteerde bevindingen in een doorlopend langetermijnonderzoek bij te werken door GPT-3.5, GPT-4 en andere LLM's regelmatig te evalueren op diverse taken in de loop van de tijd. Voor gebruikers of bedrijven die afhankelijk zijn van LLM-services als onderdeel van hun lopende workflow, raden we aan dat ze vergelijkbare monitoringanalyses implementeren als wij hier doen voor hun applicaties, "