TensorRT-LLM menghadirkan komputasi AI lokal ke GPU NVIDIA
Apa yang perlu Anda ketahui
- TensorRT-LLM menambahkan dukungan API Obrolan OpenAI untuk desktop dan laptop dengan GPU RTX mulai dari VRAM 8 GB.
- Pengguna dapat memproses kueri LLM lebih cepat dan secara lokal tanpa mengunggah kumpulan data ke cloud.
- NVIDIA memadukannya dengan "Retrieval-Augmented Generation" (RAG), sehingga memungkinkan lebih banyak kasus penggunaan LLM yang dapat disesuaikan.
Selama konferensi Microsoft Ignite hari ini, NVIDIA mengumumkan pembaruan untuk TensorRT-LLM mereka, yang diluncurkan pada bulan Oktober. Pengumuman utama hari ini adalah bahwa fitur TensorRT-LLM kini mendapatkan dukungan untuk LLM API, khususnya OpenAI Chat API, yang merupakan yang paling banyak digunakan. terkenal saat ini, dan mereka juga telah berupaya meningkatkan performa dengan TensorRT-LLM untuk mendapatkan performa per token yang lebih baik pada GPU mereka.
Ada pengumuman tersier yang cukup menarik juga. NVIDIA akan menyertakan Retrieval-Augmented Generation dengan TensorRT-LLM. Hal ini memungkinkan LLM menggunakan sumber data eksternal untuk basis pengetahuannya dibandingkan mengandalkan apa pun secara online—fitur yang sangat dibutuhkan untuk AI.
Apa itu TensorRT-LLM?
BACA LEBIH LANJUT DARI IGNITE 2023
- Microsoft membuat chip Arm-nya sendiri
- Copilot hadir di seluruh Microsoft 365
- Bing Chat berganti nama menjadi Copilot
- Microsoft Loop sekarang tersedia secara umum
- Microsoft Mesh dan Ruang Immersive
- Microsoft Planner menggabungkan To Do dan Project
- Microsoft meluncurkan Kopilot Studio
- Kopilot Keamanan Microsoft
- Aplikasi web kopilot ditayangkan
NVIDIA baru-baru ini meluncurkan NVIDIA TensorRT-LLM, perpustakaan sumber terbuka yang memungkinkan komputasi lokal LLM pada perangkat keras NVIDIA. NVIDIA menggembar-gemborkan hal ini untuk mendapatkan privasi dan efisiensi saat menangani kumpulan data besar atau informasi pribadi. Amankah informasi tersebut dikirim melalui API seperti API Obrolan OpenAI. Anda dapat mempelajari lebih lanjut tentang NVIDIA TensorRT-LLM di Situs pengembang NVIDIA.
Perubahan yang diumumkan hari ini pada NVIDIA TensorRT-LLM adalah penambahan API Obrolan dan kinerja OpenAI peningkatan untuk model LLM dan AI yang didukung sebelumnya seperti Llama 2 dan Difusi Stabil melalui DirectML perangkat tambahan.
Teknologi dan komputasi ini dapat dilakukan secara lokal melalui Meja Kerja AI NVIDIA. "Perangkat yang terpadu dan mudah digunakan ini memungkinkan pengembang dengan cepat membuat, menguji, dan menyesuaikan model AI generatif dan LLM yang telah dilatih sebelumnya pada PC atau stasiun kerja." NVIDIA memiliki halaman pendaftaran akses awal bagi yang berminat menggunakannya.
NVIDIA TensorRT-LLM adalah perpustakaan sumber terbuka yang mempercepat dan mengoptimalkan kinerja inferensi model bahasa besar (LLM) terbaru pada platform NVIDIA AI
NVIDIA
Nvidia juga menunjukkan peningkatan kinerja per token untuk LLM seperti yang dapat kita lihat pada tolok ukur NVIDIA internal ini. Seperti biasa, berhati-hatilah terhadap tolok ukur dan pengujian pabrikan untuk pelaporan peningkatan kinerja yang akurat.
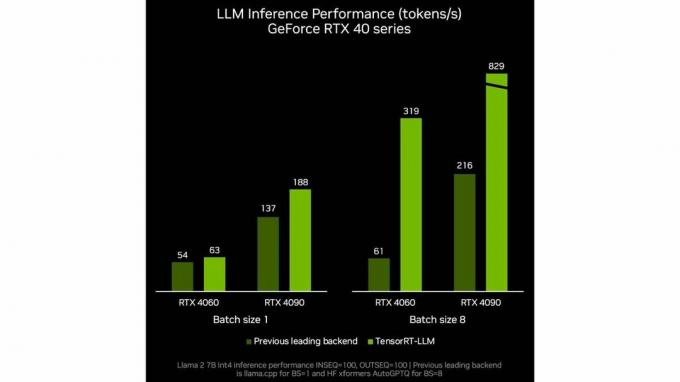
Sekarang setelah kita mengetahui TensorRT-LLM NVIDIA, mengapa ini istimewa atau berguna? Secara umum, menjalankan secara lokal pada stasiun kerja atau PC yang didukung NVIDIA kemungkinan besar akan menghasilkan jawaban yang sama terhadap pertanyaan, meskipun mungkin lebih lambat karena kurangnya daya komputasi awan.
Gambaran NVIDIA untuk kasus penggunaan ini muncul saat membahas pengumuman lain hari ini NVIDIA yaitu integrasi dengan teknologi atau fitur baru bernama Retrieval-Augmented Generasi.
Apa itu Retrieval-Augmented Generation
Istilah generasi yang ditambah pengambilan diciptakan pada a kertas oleh serangkaian penulis, dengan penulis utama adalah Patrick Lewis. Ini adalah nama yang diadopsi oleh industri untuk solusi terhadap masalah yang dihadapi setiap orang yang telah menggunakan LLM. Kedaluwarsa atau informasi yang benar tetapi salah dalam konteks pembahasan. Detail mendalam tentang cara kerja RAG dapat ditemukan di salah satu NVIDIA Ringkasan Teknis.
Pembuatan augmentasi pengambilan adalah teknik untuk meningkatkan akurasi dan keandalan model AI generatif dengan fakta yang diambil dari sumber eksternal.
Rick Merritt
Dengan memasangkan generasi yang ditambah pengambilan dengan TensorRT-LLM NVIDIA, pengguna akhir dapat menyesuaikan informasi apa yang dapat diakses oleh LLM saat menjalankan kuerinya. ChatGPT baru-baru ini diumumkan GPT khusus yang bisa menawarkan hasil serupa.
Seperti yang telah dibahas dalam artikel kami seputar GPT khusus, kemampuan untuk membuat instans LLM tujuan tunggal yang dipesan lebih dahulu dengan GPT khusus atau, dalam hal ini, instans LLM yang, menggunakan generasi yang ditambah pengambilan, hanya memiliki akses ke semua karya Charles Dickens yang diterbitkan dan tidak ada yang lain, dapat membantu dalam menciptakan LLM yang dibangun dengan tujuan, bermakna dan akurat untuk kasus penggunaan yang berbeda.
Akankah TensorRT-LLM bermanfaat?
Apa artinya semua ini bersama-sama? Ada beberapa peluang nyata agar hal ini dapat dimanfaatkan secara bermakna. Seberapa mudah penerapannya, atau seberapa aman datanya? Hanya waktu yang akan memberitahu. Terdapat potensi peningkatan AI, terutama di tingkat perusahaan alur kerja, menawarkan akses yang lebih mudah ke informasi yang rumit, dan membantu karyawan tugas yang menantang.
Meskipun tugas ini akan dijalankan secara lokal, tugas tersebut akan tetap melalui API LLM normal, yang akan menghadapi batasan dan batasan konten yang sama seperti yang dihadapi sekarang. Namun, karena teknologi seperti TensorRT-LLM dari NVIDIA mempercepat penggunaan LLM secara offline, seseorang dapat mengintegrasikannya dengan sesuatu seperti GPT Jahat, yang tidak memiliki batasan dalam tindakannya dan saat ini digunakan untuk membuat malware dan membantu serangan dunia maya, potensi AI untuk melakukan kerusakan nyata semakin besar.
Apa pendapat Anda tentang pembaruan NVIDIA pada TensorRT-LLM? Dapatkah Anda memikirkan kegunaannya yang saya lewatkan? Beri tahu kami di komentar.