क्या चैटजीपीटी/बिंग चैट मूर्ख हो गया है? इस अध्ययन के अनुसार, हो सकता है.
आपको क्या जानने की आवश्यकता है
- स्टैनफोर्ड के शोधकर्ताओं द्वारा किए गए एक अध्ययन से ओपनएआई के चैटबॉट के प्रदर्शन में गिरावट देखी गई है।
- शोधकर्ताओं ने यह निर्धारित करने के लिए चार प्रमुख प्रदर्शन संकेतकों का उपयोग किया कि जीपीटी-4 और जीपीटी-3.5 बेहतर हो रहे हैं या बदतर।
- दोनों एलएलएम विभिन्न श्रेणियों में विभिन्न प्रदर्शन और व्यवहार प्रदर्शित करते हैं।
इस साल की शुरुआत में, के दरवाजे जनरेटिव एआई अवसरों की एक नई वास्तविकता को सामने लाते हुए, व्यापक रूप से खुला। माइक्रोसॉफ्ट का नया बिंग और ओपनएआई का चैटजीपीटी सबसे आगे रहे हैं, अन्य कंपनियां भी समान मॉडल और पुनरावृत्तियों का बारीकी से अनुसरण कर रही हैं।
जबकि OpenAI अपने उपयोगकर्ता अनुभव को बढ़ाने के लिए अपने AI-संचालित चैटबॉट में नए अपडेट और सुविधाओं को आगे बढ़ाने में व्यस्त है, स्टैनफोर्ड के शोधकर्ताओं का एक समूह नया रहस्योद्घाटन वह चैटजीपीटी मूर्ख हो गया है पिछले कुछ महीनों में.
शोध दस्तावेज़ "चैटजीपीटी का व्यवहार समय के साथ कैसे बदल रहा है?" लिंगजियाओ चेन, मातेई ज़हरिया और जेम्स ज़ू द्वारा स्टैनफोर्ड यूनिवर्सिटी और यूसी बर्कले बताते हैं कि पिछले कुछ समय में चैटबॉट की प्रमुख कार्यप्रणाली किस तरह खराब हो गई है महीने.
हाल तक, चैटजीपीटी पर भरोसा था OpenAI का GPT-3.5 मॉडल, जिसने वेब पर विशाल संसाधनों तक उपयोगकर्ता की पहुंच को सीमित कर दिया क्योंकि यह सितंबर 2021 तक की जानकारी तक ही सीमित थी। और जबकि OpenAI के पास है iOS ऐप के लिए चैटजीपीटी में बिंग के साथ ब्राउज की शुरुआत हुई ब्राउज़िंग अनुभव को बेहतर बनाने के लिए, सुविधा तक पहुँचने के लिए आपको अभी भी चैटजीपीटी प्लस सदस्यता की आवश्यकता होगी।
GPT-3.5 और GPT-4 को उपयोगकर्ताओं के फीडबैक और डेटा का उपयोग करके अपडेट किया जाता है, हालाँकि, यह स्थापित करना असंभव है कि यह वास्तव में कैसे किया जाता है। यकीनन, चैटबॉट्स की सफलता या विफलता उनकी सटीकता से निर्धारित होती है। इस आधार पर, स्टैनफोर्ड के शोधकर्ताओं ने इन मॉडलों के मार्च और जून संस्करणों के व्यवहार का मूल्यांकन करके इन मॉडलों के सीखने की अवस्था को समझने का प्रयास किया।
यह निर्धारित करने के लिए कि चैटजीपीटी समय के साथ बेहतर हो रहा है या बदतर, शोधकर्ताओं ने इसकी क्षमताओं को मापने के लिए निम्नलिखित तकनीकों का उपयोग किया:
- गणित की समस्याओं को हल करना
- संवेदनशील/खतरनाक प्रश्नों का उत्तर देना
- कोड जनरेट करना
- दृश्य तर्क
शोधकर्ताओं ने इस बात पर प्रकाश डाला कि उपरोक्त कार्यों को "विविध और उपयोगी" दर्शाने के लिए सावधानीपूर्वक चुना गया था इन एलएलएम की क्षमताएं।" लेकिन बाद में उन्होंने निर्धारित किया कि उनका प्रदर्शन और व्यवहार पूरी तरह से सही था अलग। उन्होंने आगे कहा कि कुछ कार्यों पर उनके प्रदर्शन पर नकारात्मक प्रभाव पड़ा है।
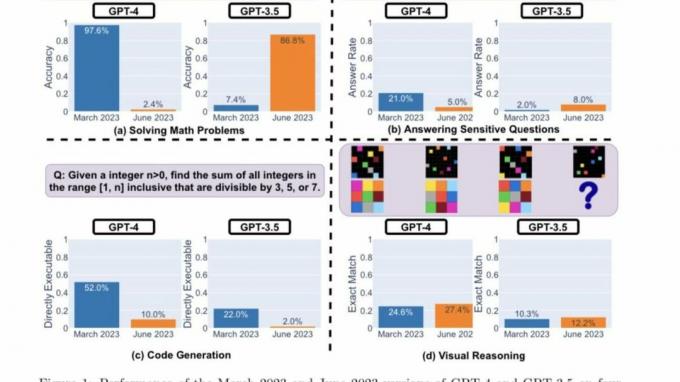
यहां है ये शोधकर्ताओं द्वारा मुख्य निष्कर्ष ऊपर हाइलाइट किए गए चार प्रकार के कार्यों पर GPT-4 और GPT-3.5 के मार्च 2023 और जून 2023 संस्करणों के प्रदर्शन का मूल्यांकन करने के बाद:
संक्षेप में, समय के साथ प्रदर्शन में कई दिलचस्प बदलाव आते हैं। उदाहरण के लिए, GPT-4 (मार्च 2023) अभाज्य संख्याओं (सटीकता 97.6%) की पहचान करने में बहुत अच्छा था, लेकिन GPT-4 (जून 2023) इन्हीं प्रश्नों (सटीकता 2.4%) पर बहुत खराब था। दिलचस्प बात यह है कि इस कार्य में GPT-3.5 (जून 2023) GPT-3.5 (मार्च 2023) से काफी बेहतर था। हमें उम्मीद है कि डेटासेट और पीढ़ियों को जारी करने से समुदाय को यह समझने में मदद मिल सकती है कि एलएलएम सेवाएं कैसे बेहतर होती हैं। उपरोक्त आंकड़ा एक [मात्रात्मक] सारांश देता है।
स्टैनफोर्ड शोधकर्ता
अदाकारी का समीक्षण
सबसे पहले, दोनों मॉडलों को एक गणित समस्या को हल करने का काम सौंपा गया था, जिस पर शोधकर्ताओं ने बारीकी से निगरानी रखी मार्च और जून संस्करणों के बीच GPT-4 और GPT-3.5 की सटीकता और उत्तर ओवरलैप मॉडल। और यह स्पष्ट था कि जीपीटी-4 मॉडल ने चेन-ऑफ-थॉट प्रॉम्प्ट का पालन करते हुए और अंततः मार्च में सही उत्तर देते हुए, प्रदर्शन में भारी गिरावट देखी। हालाँकि, उन्हीं परिणामों को जून में दोहराया नहीं जा सका क्योंकि मॉडल ने विचार-श्रृंखला निर्देश को छोड़ दिया और बिल्कुल गलत प्रतिक्रिया दी।

जहां तक जीपीटी-3.5 का सवाल है, यह विचार-श्रृंखला प्रारूप पर कायम रहा लेकिन शुरू में गलत उत्तर दिया। हालाँकि, इस मुद्दे को जून में ठीक कर लिया गया था, जिसमें मॉडल के प्रदर्शन में सुधार दिखाई दे रहा था।
"जीपीटी-4 की सटीकता मार्च में 97.6% से गिरकर जून में 2.4% हो गई, और जीपीटी-3.5 की सटीकता में बड़ा सुधार हुआ, 7.4% से 86.8% तक। इसके अलावा, GPT-4 की प्रतिक्रिया बहुत अधिक सघन हो गई: इसकी औसत वर्बोसिटी (उत्पन्न वर्णों की संख्या) मार्च में 821.2 से घटकर जून में 3.8 हो गई। दूसरी ओर, GPT-3.5 की प्रतिक्रिया लंबाई में लगभग 40% की वृद्धि हुई। उनके मार्च और जून संस्करणों के बीच उत्तर ओवरलैप भी दोनों सेवाओं के लिए छोटा था।" स्टैनफोर्ड शोधकर्ताओं ने कहा। उन्होंने आगे असमानताओं के लिए "विचारों की श्रृंखला के प्रभावों के बहाव" को जिम्मेदार ठहराया।
दोनों एलएलएम ने मार्च में संवेदनशील सवालों के बारे में पूछे जाने पर विस्तृत प्रतिक्रिया दी, जिसमें भेदभाव के निशान वाले संकेतों का जवाब देने में असमर्थता का हवाला दिया गया। वहीं, जून में दोनों मॉडल्स ने एक ही सवाल का जवाब देने से साफ इनकार कर दिया था।
Reddit पर r/ChatGPT समुदाय के उपयोगकर्ताओं ने रिपोर्ट के प्रमुख निष्कर्षों के बारे में भावनाओं और सिद्धांतों का मिश्रण व्यक्त किया, जैसा कि नीचे प्रकाश डाला गया है:
ओपनएआई चैटजीपीटी चलाने की लागत कम करने की कोशिश कर रहा है, क्योंकि उन्हें बहुत सारा पैसा खोना पड़ रहा है। इसलिए वे कम संसाधनों के साथ समान गुणवत्ता वाले उत्तर प्रदान करने और उनका भरपूर परीक्षण करने के लिए जीपीटी में बदलाव कर रहे हैं। यदि वे प्रतिगमन देखते हैं, तो वे पीछे हट जाते हैं और कुछ अलग करने का प्रयास करते हैं। तो उनके विचार में, यह कोई बेवकूफ़ नहीं हुआ, लेकिन यह बहुत सस्ता हो गया। समस्या यह है कि कोई भी परीक्षण पूरी तरह से समझ में नहीं आता है और यदि वे परीक्षण सूट पर थोड़ा विस्तार करते हैं तो इससे निश्चित रूप से मदद मिलेगी। इसलिए जबकि यह उनके परीक्षण पर समान है, यह अन्य परीक्षणों पर बहुत खराब हो सकता है, जैसे कि पेपर में। इसीलिए हम उपयोग के मामले के आधार पर फीडबैक में भिन्नता भी देखते हैं - कुछ लोग कसम खा सकते हैं कि यह वही है, दूसरों के लिए, यह भयानक हो गया है
टुकपेक, रेडिट
यह अध्ययन कितना सटीक है यह निर्धारित करना अभी भी जल्दबाजी होगी। इन रुझानों का अध्ययन करने के लिए और अधिक बेंचमार्क आयोजित करने की आवश्यकता है। लेकिन इन निष्कर्षों को नजरअंदाज करते हुए और क्या समान परिणामों को अन्य प्लेटफार्मों पर दोहराया जा सकता है, जैसे कि बिंग चैट, असंभव है।
जैसा कि आपको याद होगा, बिंग चैट के लॉन्च के कुछ हफ्ते बाद, कई उपयोगकर्ताओं ने ऐसे उदाहरणों का हवाला दिया जहां चैटबॉट मौजूद था अशिष्ट या प्रश्नों का बिल्कुल गलत उत्तर दिया. बदले में, इससे उपयोगकर्ताओं ने टूल की विश्वसनीयता और सटीकता पर सवाल उठाया, जिससे माइक्रोसॉफ्ट को इस समस्या की पुनरावृत्ति को रोकने के लिए विस्तृत उपाय करने के लिए प्रेरित किया गया। माना जाता है कि, कंपनी ने लगातार प्लेटफ़ॉर्म पर नए अपडेट पेश किए हैं, और अनेक सुधारों का उल्लेख किया जा सकता है.
स्टैनफोर्ड के शोधकर्ताओं ने कहा:
"हमारे निष्कर्ष दर्शाते हैं कि GPT-3.5 और GPT-4 का व्यवहार अपेक्षाकृत कम समय में काफी भिन्न हो गया है। यह उत्पादन अनुप्रयोगों में एलएलएम के व्यवहार का निरंतर मूल्यांकन और आकलन करने की आवश्यकता पर प्रकाश डालता है। हम समय के साथ विविध कार्यों पर जीपीटी-3.5, जीपीटी-4 और अन्य एलएलएम का नियमित मूल्यांकन करके चल रहे दीर्घकालिक अध्ययन में यहां प्रस्तुत निष्कर्षों को अद्यतन करने की योजना बना रहे हैं। उन उपयोगकर्ताओं या कंपनियों के लिए जो अपने चल रहे वर्कफ़्लो में एक घटक के रूप में एलएलएम सेवाओं पर भरोसा करते हैं, हम अनुशंसा करते हैं कि उन्हें समान निगरानी विश्लेषण लागू करना चाहिए जैसा कि हम यहां उनके अनुप्रयोगों के लिए करते हैं।"