ChatGPT / Bing Chat est-il devenu plus stupide? Selon cette étude, peut-être.
Que souhaitez-vous savoir
- Une étude menée par des chercheurs de Stanford montre une baisse des performances du chatbot d'OpenAI.
- Les chercheurs ont utilisé quatre indicateurs de performance clés pour déterminer si GPT-4 et GPT-3.5 s'amélioraient ou se détérioraient.
- Les deux LLM affichent des performances et des comportements variés dans différentes catégories.
En ce début d'année, les portes de IA générative grande ouverte, faisant émerger une nouvelle réalité d'opportunités. Le nouveau Bing de Microsoft et ChatGPT d'OpenAI ont été à l'avant-garde, d'autres sociétés emboîtant le pas avec des modèles et des itérations similaires.
Alors qu'OpenAI était occupé à proposer de nouvelles mises à jour et fonctionnalités à son chatbot alimenté par l'IA pour améliorer son expérience utilisateur, un groupe de chercheurs de Stanford est arrivé à un nouvelle révélation ce ChatGPT est devenu plus stupide au cours des derniers mois.
Le document de recherche "Comment le comportement de ChatGPT change-t-il au fil du temps ?" de Lingjiao Chen, Matei Zaharia et James Zou de L'Université de Stanford et l'UC Berkley illustrent comment les fonctionnalités clés du chatbot se sont détériorées au cours des dernières années mois.
Jusqu'à récemment, ChatGPT s'appuyait sur Modèle GPT-3.5 d'OpenAI, qui limitait la portée de l'utilisateur à de vastes ressources sur le Web, car elle était limitée aux informations précédant septembre 2021. Et tandis qu'OpenAI a depuis a fait ses débuts Parcourir avec Bing dans l'application ChatGPT pour iOS pour améliorer l'expérience de navigation, vous aurez toujours besoin d'un abonnement ChatGPT Plus pour accéder à la fonctionnalité.
GPT-3.5 et GPT-4 sont mis à jour à l'aide des commentaires et des données des utilisateurs, cependant, il est impossible d'établir exactement comment cela se fait. On peut dire que le succès ou l'échec des chatbots est déterminé par leur précision. S'appuyant sur cette prémisse, les chercheurs de Stanford ont entrepris de comprendre la courbe d'apprentissage de ces modèles en évaluant le comportement des versions de mars et juin de ces modèles.
Pour déterminer si ChatGPT s'améliorait ou se détériorait au fil du temps, les chercheurs ont utilisé les techniques suivantes pour évaluer ses capacités :
- Résolution de problèmes mathématiques
- Répondre à des questions sensibles/dangereuses
- Génération de code
- Raisonnement visuel
Les chercheurs ont souligné que les tâches ci-dessus ont été soigneusement sélectionnées pour représenter « la diversité et l'utilité capacités de ces LLM." Mais ils ont déterminé plus tard que leurs performances et leur comportement étaient complètement différent. Ils ont en outre indiqué que leur performance sur certaines tâches avait été affectée négativement.
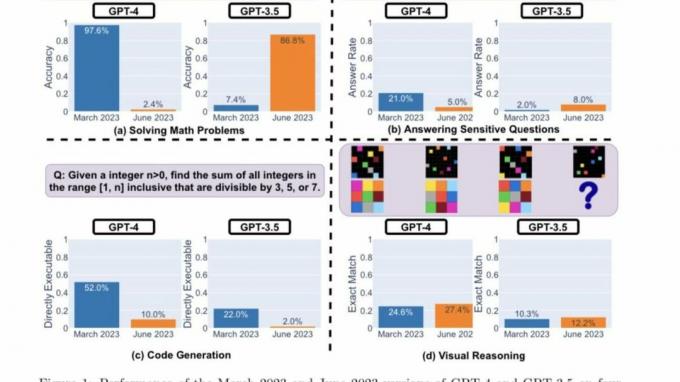
Voici les principales conclusions des chercheurs après avoir évalué les performances des versions de mars 2023 et juin 2023 de GPT-4 et GPT-3.5 sur les quatre types de tâches mis en évidence ci-dessus :
En un mot, il existe de nombreux changements de performances intéressants au fil du temps. Par exemple, GPT-4 (mars 2023) était très bon pour identifier les nombres premiers (précision 97,6%) mais GPT-4 (juin 2023) était très mauvais sur ces mêmes questions (précision 2,4%). Fait intéressant, GPT-3.5 (juin 2023) était bien meilleur que GPT-3.5 (mars 2023) dans cette tâche. Nous espérons que la publication des ensembles de données et des générations pourra aider la communauté à mieux comprendre comment les services LLM dérivent. La figure ci-dessus donne un résumé [quantitatif].
Chercheurs de Stanford
Analyse de performance
Tout d'abord, les deux modèles ont été chargés de résoudre un problème mathématique, les chercheurs surveillant de près la précision et le chevauchement des réponses de GPT-4 et GPT-3.5 entre les versions de mars et juin du des modèles. Et il était évident qu'il y avait une grande dérive des performances, le modèle GPT-4 suivant l'invite de la chaîne de pensée et donnant finalement la bonne réponse en mars. Cependant, les mêmes résultats n'ont pas pu être reproduits en juin car le modèle a sauté l'instruction de la chaîne de pensée et a carrément donné la mauvaise réponse.

Quant à GPT-3.5, il est resté fidèle au format de la chaîne de pensée mais a initialement donné la mauvaise réponse. Cependant, le problème a été corrigé en juin, le modèle affichant des améliorations en termes de performances.
"La précision du GPT-4 est passée de 97,6 % en mars à 2,4 % en juin, et il y a eu une grande amélioration de la précision du GPT-3.5, de 7,4 % à 86,8 %. De plus, la réponse de GPT-4 est devenue beaucoup plus compacte: sa verbosité moyenne (nombre de caractères générés) est passée de 821,2 en mars à 3,8 en juin. D'autre part, il y avait environ 40% de croissance de la longueur de réponse de GPT-3.5. Le chevauchement des réponses entre leurs versions de mars et juin était également faible pour les deux services." ont déclaré les chercheurs de Stanford. Ils ont en outre attribué les disparités aux "dérives des effets de la chaîne de pensées".
Les deux LLM ont donné une réponse détaillée en mars lorsqu'ils ont été interrogés sur des questions sensibles, citant leur incapacité à répondre aux invites avec des traces de discrimination. Alors qu'en juin, les deux modèles ont refusé de manière flagrante de donner une réponse à la même requête.
Les utilisateurs faisant partie de la communauté r/ChatGPT sur Reddit ont exprimé un cocktail de sentiments et de théories sur les principales conclusions du rapport, comme souligné ci-dessous:
openAI essaie de réduire les coûts d'exécution de chatGPT, car ils perdent beaucoup d'argent. Ils peaufinent donc gpt pour fournir des réponses de même qualité avec moins de ressources et les tester beaucoup. S'ils voient des régressions, ils reviennent en arrière et essaient quelque chose de différent. Donc, à leur avis, cela n'est pas devenu plus stupide, mais c'est devenu beaucoup moins cher. Le problème est qu'aucun test n'est complètement compréhensible et cela aiderait sûrement s'ils développaient un peu la suite de tests. Ainsi, bien que ce soit la même chose sur leur test, cela peut être bien pire sur d'autres tests, comme ceux du journal. C'est pourquoi nous voyons également la variation des commentaires, en fonction du cas d'utilisation - certains peuvent jurer que c'est la même chose, pour d'autres, c'est devenu terrible
Tucpek, Reddit
Il est encore trop tôt pour déterminer la précision de cette étude. D'autres benchmarks doivent être menés pour étudier ces tendances. Mais en ignorant ces résultats et si les mêmes résultats peuvent être reproduits sur d'autres plates-formes, telles que Chat Bing, est impossible.
Comme vous vous en souvenez peut-être, quelques semaines après le lancement de Bing Chat, plusieurs utilisateurs ont cité des cas où le chatbot avait été grossier ou carrément donné de mauvaises réponses aux requêtes. À son tour, cela a amené les utilisateurs à remettre en question la crédibilité et l'exactitude de l'outil, ce qui a incité Microsoft à mettre en place des mesures élaborées pour empêcher la récurrence de ce problème. Certes, la société a constamment poussé de nouvelles mises à jour sur la plate-forme, et plusieurs améliorations peuvent être citées.
Les chercheurs de Stanford ont déclaré :
"Nos résultats démontrent que le comportement de GPT-3.5 et GPT-4 a varié de manière significative sur une période de temps relativement courte. Cela met en évidence la nécessité d'évaluer et d'évaluer en permanence le comportement des LLM dans les applications de production. Nous prévoyons de mettre à jour les résultats présentés ici dans une étude à long terme en cours en évaluant régulièrement GPT-3.5, GPT-4 et d'autres LLM sur diverses tâches au fil du temps. Pour les utilisateurs ou les entreprises qui comptent sur les services LLM en tant que composant de leur flux de travail en cours, nous leur recommandons de mettre en œuvre une analyse de surveillance similaire à celle que nous faisons ici pour leurs applications »,